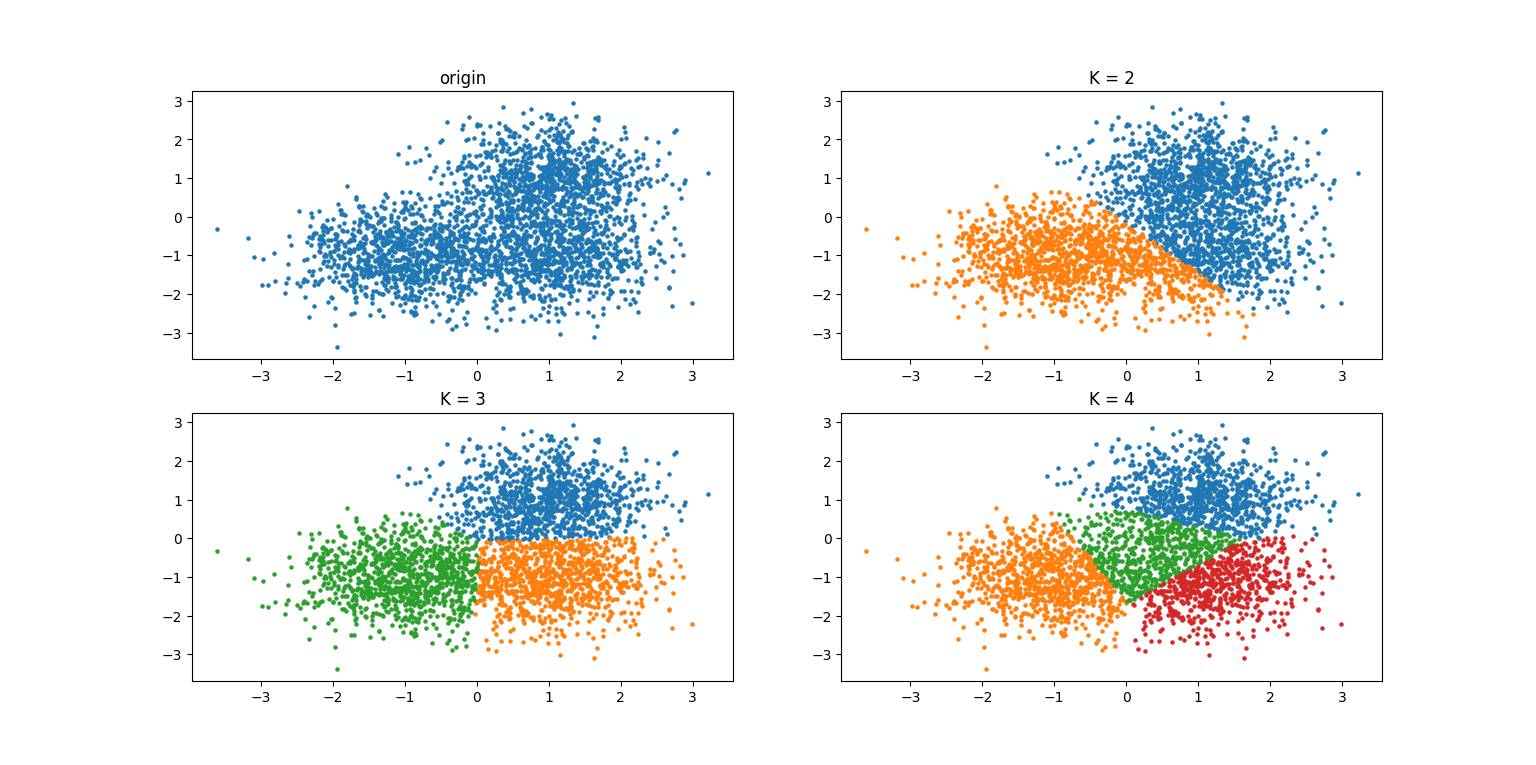
K-means 大致原理
'''
# System --> Windows & Python3.10.0
# File ----> kmeans.py
# Author --> Illusionna
# Create --> 2024/08/08 23:38:11
'''
# -*- Encoding: UTF-8 -*-
import os
import math
import random
import platform
import collections
import pandas as pd
import matplotlib.pyplot as plt
def cls() -> None:
os.system('')
try:
os.system(
{'Windows': 'cls', 'Linux': 'clear'}[platform.system()]
)
except:
print('\033[H\033[J', end='')
cls()
def Load(dir: str, header: int | None) -> pd.DataFrame:
"""
加载数据函数, 返回到读取的 csv 格式数据.
"""
df = pd.read_csv(dir, header=header)
return df
class Kmeans:
"""
K-means 聚类.
"""
def __init__(self, data: pd.DataFrame, K: int) -> None:
self.shape = data.shape
self.data: list = data.values.tolist()
assert K > 1, f'聚类簇至少 2 个以上, 但检测到数目为 "{K}" 异常.'
self.K = K
@staticmethod
def RandomSelect(L: list, N: int) -> list:
"""
随机初始化选择 K 个不重复的点列.
>>> L = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> RandomSelect(L, 3)
>>> [3, 7, 5]
"""
return random.sample(L, N)
@staticmethod
def Euclidean(a: list, b: list) -> float:
"""
计算欧氏空间中的距离.
>>> a = [0, 1, 0, 0]
>>> b = [1, 0, 0, 0]
>>> Euclidean(a, b)
>>> 1.4142135623730951
"""
return math.sqrt(sum((x - y) ** 2 for x, y in zip(a, b)))
@staticmethod
def Center(L: list[list]) -> list:
"""
计算簇的重心, 即平均位置.
>>> L = [[1, 4, -1], [2, 5, 0], [3, 6, 1]]
>>> Center(L)
>>> [2, 5, 0]
"""
return [sum(x) / len(L) for x in zip(*L)]
@staticmethod
def Loss(a: list[list], b: list[list]) -> float:
"""
自定义重心的损失误差.
>>> a = [[81.0, 82.0], [23.5, 27.0]]
>>> b = [[80.0, 80.0], [23.0, 27.0]]
>>> Loss(a, b)
>>> Euclidean([81.0, 82.0], [80.0, 80.0]) + Euclidean([23.5, 27.0], [23.0, 27.0])
"""
return sum(Kmeans.Euclidean(x, y) for x, y in zip(a, b))
@staticmethod
def InitializeCluster(centers: list[list], data: list[list]) -> collections.defaultdict[list]:
"""
初始化一个簇字典.
>>> centers = [
[51, 52], [81, 82], [41, 42]
]
>>> data = [
[11, 12], [21, 22], [31, 32],
[41, 42], [51, 52], [61, 62],
[71, 72], [81, 82], [91, 92]
]
>>> InitializeCluster(centers, data)
>>> defaultdict(
,
{
0: [[51, 52], [61, 62]],
1: [[81, 82], [71, 72], [91, 92]],
2: [[41, 42], [11, 12], [21, 22], [31, 32]]
}
)
"""
ans = collections.defaultdict(list)
for k in range(0, len(centers), 1): ans[k].append(centers[k])
for i in range(0, len(data), 1):
if data[i] not in centers:
distances = [Kmeans.Euclidean(data[i], center) for center in centers]
idx = distances.index(min(distances))
ans[idx].append(data[i])
return ans
@staticmethod
def Iteration(
data: list[list],
clusters: collections.defaultdict[list],
epoch: int,
threshold: int
) -> dict:
"""
聚类迭代, epoch 或 threshold 越大效果越好.
>>> clusters = defaultdict(
,
{
0: [[51, 52], [61, 62]],
1: [[81, 82], [71, 72], [91, 92]],
2: [[41, 42], [11, 12], [21, 22], [31, 32]]
}
)
>>> Iteration(clusters, 100, 7)
>>> {
0: [[11, 12], [21, 22], [31, 32]],
1: [[41, 42], [51, 52], [61, 62]],
2: [[71, 72], [81, 82], [91, 92]]
}
"""
ABSOLUTE_ERROR = 1e-7
label = 0
errors = list()
last_centers: list = [Kmeans.Center(clusters[n]) for n in clusters.keys()]
for _ in range(0, epoch, 1):
centers: list = [Kmeans.Center(clusters[n]) for n in clusters.keys()]
errors.append(Kmeans.Loss(last_centers, centers))
if len(errors) > 2:
if abs(errors[-1] - errors[-2]) < ABSOLUTE_ERROR:
label = -~label
if label >= threshold:
# 超过 threshold 次 errors 的最后一次误差与上次接近, 则收敛, 提前退出.
return dict(clusters)
for k in range(0, len(centers), 1): clusters[k] = []
for idx, center in enumerate(centers):
if center in data:
clusters[idx].append(center)
for i in range(0, len(data), 1):
if data[i] not in centers:
distances = [Kmeans.Euclidean(data[i], center) for center in centers]
clusters[distances.index(min(distances))].append(data[i])
# 迭代 epoch 次数耗尽后, 强制退出.
return dict(clusters)
def Cluster(self, epoch: int = 100, threshold: int = 3) -> dict:
return Kmeans.Iteration(
data = self.data,
clusters = Kmeans.InitializeCluster(
centers = Kmeans.RandomSelect(self.data, self.K),
data = self.data
),
epoch = epoch,
threshold = threshold
)
if __name__ == '__main__':
# # ---------------------test---------------------
# df = pd.DataFrame(
# [
# [1, 12, 1],
# [21, 22, 1],
# [31, 32, 1],
# [41, 42, 1],
# [51, 52, 1],
# [61, 62, 1],
# [71, 72, 1],
# [81, 82, 1],
# [91, 92, 1]
# ]
# )
# obj = Kmeans(df, K=3)
# result: dict = obj.Cluster(epoch=12)
# print(result)
# # -----------------------------------------------
df = Load('./data.csv', header=0)
plt.subplot(2, 2, 1)
plt.scatter(df.iloc[:, 0], df.iloc[:, 1], s=5)
plt.title('origin')
plt.subplot(2, 2, 2)
obj = Kmeans(df, K=2)
result: dict = obj.Cluster(epoch=12)
for value in result.values():
X, Y = zip(*value)
plt.scatter(X, Y, s=5)
plt.title('K = 2')
plt.subplot(2, 2, 3)
obj = Kmeans(df, K=3)
result: dict = obj.Cluster(epoch=12)
for value in result.values():
X, Y = zip(*value)
plt.scatter(X, Y, s=5)
plt.title('K = 3')
plt.subplot(2, 2, 4)
obj = Kmeans(df, K=4)
result: dict = obj.Cluster(epoch=12)
for value in result.values():
X, Y = zip(*value)
plt.scatter(X, Y, s=5)
plt.title('K = 4')
plt.show() GNU GPLv3 project by Illusionna: orzzz.net